Model and Cost Function¶
Model Representation¶
\(x^{(i)}\) denotes the input variables also called as input features \(y^{(i)}\) denotes the output or target variable that we are trying to predict
A pair \({(x^{(i)}, y^{(i)})}\) is called a training example, and the dataset that we’ll be using to learn— a list of m training examples \({(x^{(i)}, y^{(i)})}\); i=1,…,m— is called a training set.
To describe the supervised learning problem slightly more formally, our goal is, given a training set, to learn a function \(h : X → Y\) so that \(h(x)\) is a good predictor for the corresponding value of y.
\(h_\theta(x) = \theta_0 + \theta_1 x\). This function h is called a hypothesis.

When the target variable that we’re trying to predict is continuous, such as in our housing example, we call the learning problem a regression problem. When y can take on only a small number of discrete values (such as if, given the living area, we wanted to predict if a dwelling is a house or an apartment, say), we call it a classification problem.
Cost Function¶
We can measure the accuracy of our hypothesis function by using a cost function. This takes an average difference of all the results of the hypothesis with inputs from x’s and the actual output y’s.
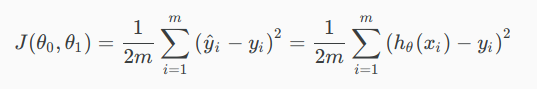
This function is otherwise called the “Squared error function”, or “Mean squared error”